はじめに:
このドキュメントには、Super Computing 2017で行ったAlpha Data社のFPGAベースのVolume Ray-Castingのデモについての説明が含まれています。このデモでは、Vivado HLSとAlpha DataのADB3 PCIe Bridgeを利用して、PCI Expressインタフェースを備えたFPGAカードに計算集中型のアルゴリ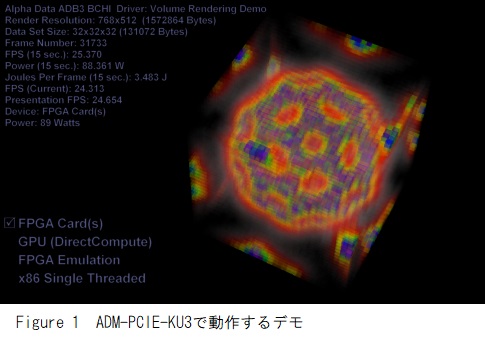 ズムを実装する方法を示します。使用したシステムは、スケーラブルかつ電力効率的であることが示されており、FPGAプラットフォームは、トップレベルのIPインテグレータ(IPI)システム、オン/オフチップデータフロー用IPコア、ボード固有のホスト通信の組み合わせで構築されています。これらは、C ++で記述され、ザイリンクスのVivado HLSツールで合成されたレイキャスティングIPコアと組み合わされています。これらのIPの重要な側面について説明します。
ズムを実装する方法を示します。使用したシステムは、スケーラブルかつ電力効率的であることが示されており、FPGAプラットフォームは、トップレベルのIPインテグレータ(IPI)システム、オン/オフチップデータフロー用IPコア、ボード固有のホスト通信の組み合わせで構築されています。これらは、C ++で記述され、ザイリンクスのVivado HLSツールで合成されたレイキャスティングIPコアと組み合わされています。これらのIPの重要な側面について説明します。
このアルゴリズムには次の3つのフェーズがあります。
1)データをアップロードしてタスクを分割する
2)レンダリングアルゴリズムを実行する
3)結果をダウンロードして再組み立てする
実行段階では、出力の各ピクセルは他のピクセルとは無関係に計算できます。 これにより、タスクを分割(分解)し、ピースを複数の実行ユニットに分散させることで、スケーラビリティが簡単になります。
このデモンストレーションFPGAデザインの構造は、タスクを独立した作業項目に分解することを可能にする他の計算集中型アルゴリズムにも適しています。出力例をFigure 1に示します。
ここでは、1秒あたりの反復数に関して全体的に達成されたパフォーマンスが、使用可能なFPGAカードの数に応じてどのように変化するかを説明します。結果は、CPUに代わるものと比較してFPGA実装のエネルギー効率が向上していることを示しています。ノード内のFPGAとCPUの比率を上げてスケーリングすると、ノードレベルでのエネルギー効率がさらに向上します。現在のバージョンのデモでは、使用可能なFPGAカード数の制限はホストシステムのPCI Expressスロットの数によって決まりますが、原則としてこのタスクは異種の相互接続(イーサネットなど)を持つFPGAカードはいくつにでも分解できます。ただし、いくつかのボトルネックがシステム全体のスケーラビリティに実用上の限界を課すことが予想され、これは将来の研究で調査されるでしょう。
アーキテクチャ:
Volume Ray-Castingの実行は3つのフェーズに分けられます。
1)体積測定データセットを装置にアップロードし、レンダリングパラメータを設定する
2)Vivado HLSで生成されたIPを「C to gate」IPを使用してレンダリングアルゴリズムを実行する
3)デバイスから結果(レンダリングされた画像)をダウンロードする
学術的な観点から、フェーズ1)と3)は特に興味深いものではなく、目新しいものではありません。ただし、フェーズ2)はこのドキュメントの焦点となります。レンダリング用のパイプラインは一連のコンポーネントで構成され、各コンポーネントはC ++で記述され、Vivado HLSツールを使用してネットリストに合成されます。これらのコンポーネントは、Vivadoのブロックダイアグラムエディタが提供する配線図を使用して、ADB3 PCIeブリッジ(BCHI:Board Control and Host Interface)のインスタンスと共に接続され、Figure 2に示すような完全なレンダリングアーキテクチャを作成します。
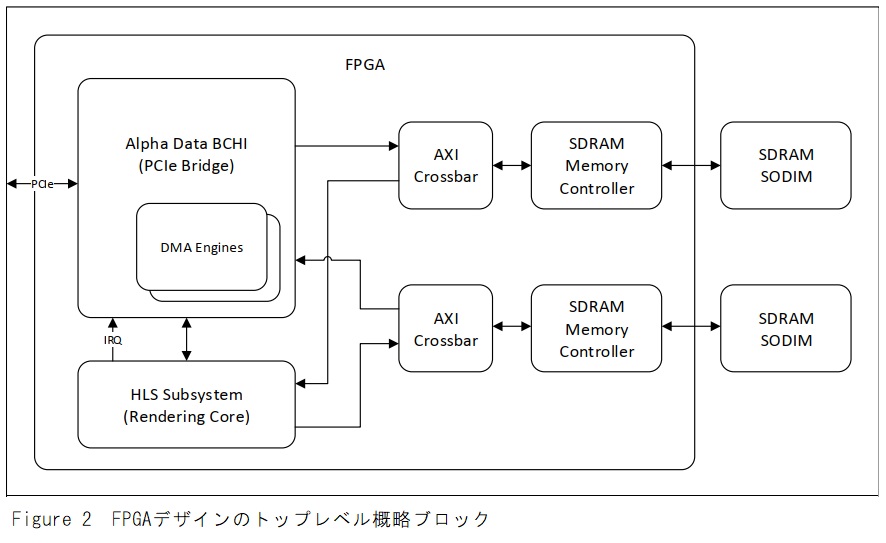
 このデモで選択されたFPGAカードはADM-PCIE-KU3です。これには、FPGA用のオフチップメモリを提供する2つのSODIMMスロットがあります。各SODIMMにはメモリコントローラが必要です。クロスバーは、(a)ホストシステム(データと結果のアップロードとダウンロードのため)、および(b)レンダリングアルゴリズムを実行するHLSサブシステムの両方によって、メモリへの共有アクセスを可能にします。
このデモで選択されたFPGAカードはADM-PCIE-KU3です。これには、FPGA用のオフチップメモリを提供する2つのSODIMMスロットがあります。各SODIMMにはメモリコントローラが必要です。クロスバーは、(a)ホストシステム(データと結果のアップロードとダウンロードのため)、および(b)レンダリングアルゴリズムを実行するHLSサブシステムの両方によって、メモリへの共有アクセスを可能にします。
各FPGAカードで、ホストインタフェースはBCHIによって提供されます。このIPは最大4つのDMAエンジンを含むPCI Expressエンドポイントを提供し、CPUがHLSサブシステムを制御するFPGA内のレジスタを読み書きすることも可能にします。ホストを中断する機能もBCHIによって提供されます。これは、作業項目の完了をホストに通知するためにHLSサブシステムによって使用されます。
レンダリングアルゴリズム:
このデモで使用されているVolume Ray-Castingアルゴリズムは次のとおりです。
レンダリングされる各フレームについて、出力画像の各ピクセルは、視点からのピクセルの位置(スクリーン上)を通る光線として投影されます。光線がピクセルの位置から投影されると、光線がデータセットのボリュームと交差するかどうかを判断するために、最初のカリング計算が実行されます(データセットで表される3次元空間を含む直方体)。結果が負の場合、出力ピクセルは背景色に設定され、それ以上の処理は不要です。体積データセット(ボクセルの3次元配列)は、体積を3次元ボクセルの集合と見なすのとは対照的に、2次元テクスチャ平面の3つのスタック、すなわちXY、XZおよびYZとして表すことができます。この表現は、アルゴリズムがどのように機能するかの鍵となります。
最初のカリングテスト(上記参照)をパスした光線は、3つの平面スタックに対してキャストされ、各平面スタックの最初のチェックで最もスクリーンに近い衝突が返されるように順序付けされます(最短の光線になります)。各スタックの最初の衝突がボリュームの境界内で検出されるまで、各スタックの衝突が繰り返されます(プレーンのサイズは無限大です)。各平面スタックについての衝突の結果を比較すると、最も早いものが次の交差点として選択される。特定の2次元平面とその2次元平面内の点が決定されると、その点はボリュームデータセット内の3次元ボクセルの座標に変換されます。次に、体積測定データを含むメモリにアクセスしてボクセルのカラー値を読み取ります。このカラー値は現在のレイのカラーとブレンドされます。ボクセルが透明な色の場合は、光線は通過します。不透明なボクセルに当たる光線、またはボリュームのより深い浸透が見えなくなるようなアルファ値になる光線は、それらが遭遇する最後の衝突を反映するように色の値を更新した後にフレームバッファに書き出されます。
3組の平面に対して終了条件:(i)不透明な衝突のために旅は終了する(ii)さらなる衝突は目に見える結果をもたらさない(iii)光線がボリュームから完全に出る、 に達するまで、平面の組のより深部まで続く光線はさらに処理されます。
この状態に達すると、それ以上光線を処理する必要はなくなり、その色の値がフレームバッファに書き出されます。すべてのピクセルが計算された(すなわち、すべての光線が投射され終了した)とき、フレームはダウンロードおよび提示(表示)の準備ができたことになります。
レンダリング実装:
上記のレンダリングアルゴリズムの説明は、どの実装も算術集約的であり、メモリへのランダムアクセスを必要とすることを示唆しています。HDLですべてをコーディングするよりも、Vivado HLSおよび他のいわゆる「C to Gates」ツールが提供する主な利点は、そのようなアルゴリズムを高級言語でコーディングできることです。
Vivado HLSを正しく使用することで非常に強力なツールになります。他のEDAツールやプログラミング言語と同様に、理解しなければならない制限事項もあります。Vivado HLSの主な強みは、複雑な算術機能を実行するためにIPブロックを迅速に開発できることです。VHDLやVerilogなどの従来のHDL言語でコーディングするには長い時間がかかります。一度記述すれば、HLSコードは簡単に変更できますが、設計への構造的な変更を必要とするHDLコードへの変更には膨大な開発期間が必要になる場合があります。たとえば、C/C++では、ソフトウェアエンジニアは複雑な算術式を評価する関数を書くのに数分かかることがあります。従来のHDL言語で同じ式をコーディングするためには、エンジニアはスペースだけでなく時間も考慮しなければならず、パイプライン化やタイミングクロージャを達成する必要性などのパフォーマンスも考慮する必要があります。
また、Vivado HLSにはいくつかの制限があります。シーケンシャルプロセッサやプロセッサの配列(GPUコアなど)用に書かれたコードを魔法のように分析することはできず、そのコードで記述されたアルゴリズムを実行するための最適なハードウェアアーキテクチャを作成することはできません。何もせずに単純にアルゴリズムをHLSコードに変換するHLSの制限を考慮すると正しい実装が作成されますが、パフォーマンスが低下します。アルゴリズムに適したアーキテクチャを作成するには、アルゴリズムをパイプライン形成できるサブコンポーネントに分解するために、何らかの分析を実行する必要があります。
次に考慮すべき点はFPGAアーキテクチャです。アルゴリズムがFPGA内のプリミティブにどのようにマッピングされる可能性があるかについての知識は、FPGAリソースを不必要に消費するのを避けるために役立ちます。
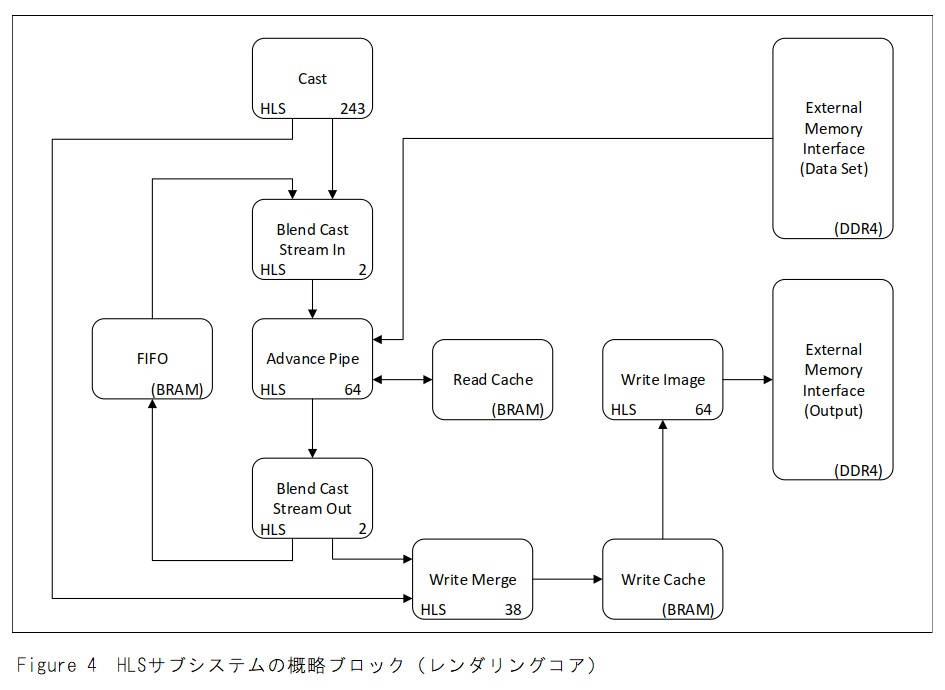
Figure 4は、HLS生成コンポーネントと非HLSコンポーネントの接続性を示しています。各HLSコンポーネントには、そのパイプラインの深さが記されています。Castコンポーネントは、ボリュームデータにキャストされる初期光線のストリームを生成します。画面上の各ピクセル(作業項目)に対して、他のコンポーネントで使用されている光線を投影して初期化するために3次元幾何学計算を実行します。処理された各作業項目は、2つの可能な出力ストリーム(i)ボリュームデータを見逃すように計算された光線のためのバイパスストリーム、(ii)ボリュームデータと交差し処理を必要とする光線のためのストリーム。のうちの1つに出力されます。
Castコンポーネントは、数学的には最も重いHLS生成コンポーネントです。HLSはこのコンポーネント用に243ステージのパイプラインを生成し、出力ストリームがブロックされていない限り、クロックサイクルごとに新しい作業項目を開始できます。作業項目が処理される割合は、繰り返し間隔(II)と呼ばれることがよくあります。キャストのレイテンシは243、IIは1です。
HLSコンポーネントのいくつかは非常に単純なストリームマージエンティティです: Blend Cast Stream Out及びBlend Cast Stream In。HDLで記述するのではなくHLS IPとして作成すると、他のHLS IPと互換性があることが保証されているインタフェースがあり、機能検証中にFPGAデザインをマイクロプロセッサでエミュレートするときに使用できます。Blend Cast Stream InとBlend Cast Stream Outの両方のIIは1です。Advance Pipeは光線が通過するボクセルに基づいて光線の色を変更するためにデータセットを介して光線を進めます。必要な計算のいくつかは、Castコンポーネントですでに実行されたものと共通しています。したがって、これらの結果を再計算する代わりに、Castコンポーネントからの結果が光線と共にデータとして渡されます。これにより、アドバンスパイプの複雑さが軽減されるため、パイプラインの長さは64だけで済みます。Castコンポーネントからのストリームに余分なバス幅が追加されると、追加のFPGA配線リソースが消費されるため、これは無償ではありません。よって、極端に広いバスはタイミングクロージャを達成するのを困難にすることがあります。
アドバンスパイプのIIは1ですが、外部メモリへのアクセスが原因で、外部メモリがすばやく応答しない場合は停止します。外部メモリへのアクセス数を減らしてストールの可能性を減らすために、BlockRAMベースのキャッシュがコンポーネントに接続されています。キャッシュの制御はHLSコードで実装されていますが、その実装を完全に制御するためにキャッシュはHDLでコーディングされています。
Advance Pipeコンポーネントを通過するたびに、光線の色に対する1つの更新が計算されます。光線がさらに処理を必要とする場合、光線はBlend Cast Stream OutコンポーネントによってFIFOコンポーネントにプッシュされ、後でAdvance Pipeに再び入ります。光線がデータセットをたどってその行程を完了した場合は、Write Mergeコンポーネントにプッシュされます。Write Mergeには2つの仕事があります。 キャストバイパスストリームまたは完成したAdvanced Pipe作業アイテムのストリームから完成した作業アイテムを取り出し、2つのストリームをマージして、そのアイテムをキャッシュに書き込みます。 このコンポーネントのIIは1です。
Write Imageコンポーネントは、ラインの準備が整ったときにWrite Cacheからキャッシュラインを書き込みます。このコンポーネントのIIは2です。メモリの幅が512ビットであるのに対し、Write Imageに入力される項目の幅は32ビットなので、ボトルネックにはなりません。したがって、Write Mergeは、システムにボトルネックを発生させることなく、最大16のIIで実行できます。
このセクションでは、Volume Ray-Castingに必要なすべてのHLSコンポーネントの概要を説明しました。 これらはそれぞれIIが1であるため(上記のように、Write Imageを除く)、最大のスループットが達成されます。
ホストインタフェース:
FPGA、Vivado、Vivado-HLSは、単一アルゴリズムの実行専用のカスタムプロセッサを構築するための効果的なツールです。しかし、実行ユニットを持つことは、そのアルゴリズムを使用するためのアプリケーションを作成するための解決策の半分に過ぎません。 問題の他の部分はどのようにしてデータを実行ユニットに出し入れするか、そしてそれを制御するかです。
Alpha DataのADB3 Bridge and Driverは、この例で示されているカスタムFPGAアクセラレータデバイスとのやり取りという共通の作業を効率化するための多数の機能を提供します。 デバイスへのダイレクトスレーブアクセス、ダイレクトメモリアクセス(DMA)(ホストとFPGAデバイス間の双方向)、割り込み処理、および共通APIを介した複数のADB3デバイスとの通信により、デバイス間でタスクを分割できます。
ホストソフトウェア:
アプリケーションのプレゼンテーション層はDirect3D(Microsoft DirectX APIの一部)を使用しています。これは、FPGAからレンダリングされたフレームを最小の待ち時間で画面に表示するために使用されています。FPGAカードからレンダリングされたフレームの提示に加えて、直接計算およびシングルスレッドx86_64バージョンのレンダリングアルゴリズムも実行することができます。
FPGAカードとの相互作用は、フレームの取得とそれらを表示することと同期させるレンダリングループにおいて実行されます。レンダリングループが繰り返されるたびに、レンダリングされたフレームがFPGAカードから収集され、ビューパラメータが更新され、次のフレームのレンダリングが開始されます。
FPGAバージョンのレンダリングルーチンを実行する際のデモアプリケーションは、システムに存在するすべてのFPGAデバイスを列挙します。レンダリングタスクは、利用可能なデバイス間で分割されます。 このアプリケーションの場合、利用可能なカード間で作業項目を均等に分割するだけです。
たとえば、システムに2枚のカードが存在する場合、フレームは2つのハーフフレームに分割され、各FPGAカードはこれらのハーフフレームの1つをレンダリングします。その後、FPGAカードからホストメモリへのDMA転送の一部としてハーフフレームが結合されてフルフレームになります。
実行と評価:
Volume Ray-Castingの例では、さまざまなパラメータを変更できます。以下に示す結果は、FPGAカードが従来のマイクロプロセッサベースの実装よりも優れている一方で、エネルギー効率が高いことを示しています。以下に詳述する結果を記録するために使用されたホストシステムは、MSI Z87-G45コンシューマクラスマザーボード上のi7-4770S 3.1GHz CPUと16 GBのDDR4 SDRAMで構成されています。電力測定は、システムに電力を供給するCorsair AX860i電源に組み込まれたセンサーを使用して行われました。各実験では、未使用のアクセラレータデバイスをシステムから削除したため、未使用のデバイスがアイドル状態で静的電力を消費することなく公平な比較を行うことができました。
以下の結果を得るために使用された体積測定データは、Figure 1のような半透明バッキーボールの32×32×32ボクセルセットである。レンダリングを15秒間連続して行い、平均フレームレート、電力、およびエネルギー消費量を記録しました。一連のFPGAカード上でのレンダリングに加えて、適切に移植されたアルゴリズムのバージョンを使用して他の2つのコンピューティングデバイス上でレンダリングも行われた。Microsoft DirectCompute下で、(i)システムのプロセッサ上の単一スレッド、および(ii)プロセッサ統合GPU。
結果:
Table 1は、さまざまなサイズの出力画像でのシステムの平均達成フレームレートを示しています。(数値が高いほど良い)。 全ての場合において、FPGAカードはCPUより性能が優れていることが分かります。
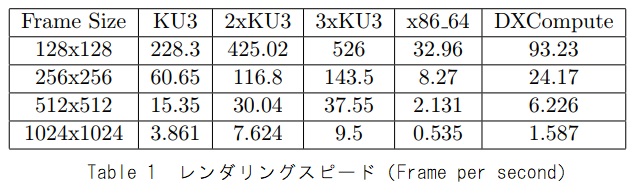
Table 2は各実験における平均出力を示しています。これはシステムの平均総電力です(出力画像の表示に使用される電力を含む)。x86_64シングルスレッドバージョンには最低の消費電力ですが、フレームレートが最も低いことを考えれば、これは驚くべきことではありません。
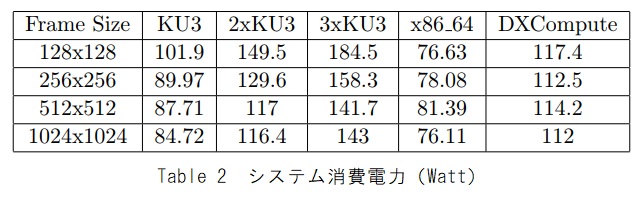
表3と表4に、各実験の各フレームと各ピクセルのエネルギーコストを示します。
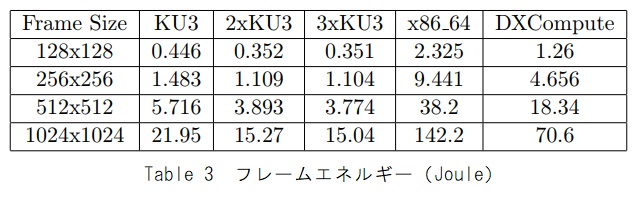
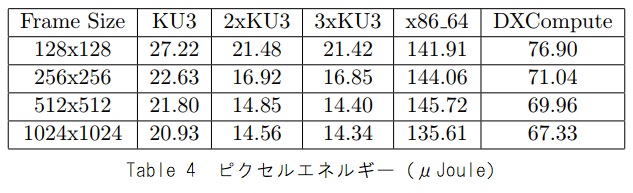
これらの結果は、FPGAカードが、このアプリケーションでx86_64 CPUよりもエネルギー効率が良く高速であることを示しています。
まとめ:
このデモでは、高度なツールを使用して計算集約型のアルゴリズムをFPGAベースのハードウェアに実装し、複数のFPGAで実行できるように拡張できることを示し、標準のx86 64 CPUと比べてエネルギー効率の高いソリューションを提供できることを検証しました。
———————————————————————–
原文ドキュメント:Alpha Data社
vrc_2017_final_2.pdf
FPGA based Volume Ray-Casting
関連製品

ADM-PCIE-9H3:Virtex UltraScale+ FPGA アクセラレータボード (PCIe)
ADM-PCIE-9H7:Virtex UltraScale+ FPGA アクセラレータボード (PCIe)
Alpha Data社について
Alpha Dataは、1993年に設立され、計算集約型アプリケーションをターゲットとした最先端のFPGAソリューションを提供しており、FPGAアクセラレータのマーケットリーダとして市場を牽引しています。主な製品はVPX、XMC、PMC、PCI、CompactPCI、PCIExpress、VXS、VMEなどのA/D, D/A, FPGAボードやCameraLink等のデジタルI/Fを搭載した信号処理ボードです。ボーイング、ロックウェルコリンズ、JPL、ロッキードマーチン、モトローラ、BAEなどのミリタリ向けやデータセンター向けに広く採用されています。Alpha Data社の詳細については、https://www.alpha-data.com/を参照してください。