 はじめに:
はじめに:
Virtex Ultrascale+広帯域幅メモリ(HBM)FPGAデバイスのリリースにより、メモリバウンドアプリケーションの全く新しい領域を開き、電力効率の良いFPGAアクセラレーションに利点をもたらします。最近のトレンドは、CPUを超えるメモリ帯域幅の大幅な利点のため、さまざまなメモリバウンドアプリケーションは高性能の並列浮動小数点演算を必要としないにもかかわらずGPUシステムに向けられています。しかし、同様の外部メモリ帯域幅を備えたFPGAの出現により柔軟性と内部メモリ帯域幅が大幅に向上し、これらの問題に対するよりカスタマイズされたエネルギー効率の高いアクセラレートソリューションが可能になりました。
VU37Pは、ザイリンクスVirtex Ultrascale+ HBMシリーズの最大規模のデバイスです。このデバイスは、Xilinx 3D Stacked Silicon Interconnectを使用して複数のFPGAダイをスタックします。これには、2つの4GB HBM Gen2 DRAMダイとともに2つの4GB HBM Gen2 DRAMダイが同じパッケージに含まれており、パッケージ内ウェーハ間の膨大な帯域幅を可能にします。単一デバイス内での大規模な並列処理機能と大規模なメモリ帯域幅のこの結合により、従来のメモリバウンドアプリケーションでのアクセラレートの要求、拡大をもたらす可能性があります。

Alpha Data ADM-PCIE-9H7は、市場で最初のVirtex Ultrascale+ VU37Pボードです。このボードは、280万の構成可能なロジックセル、60 MBの非常に柔軟なオンチップ(キャッシュ)メモリ、9024 DSPタイル(500 GFLOPSを超える倍精度のパフォーマンスが可能)、460 GB/sメモリ帯域幅、ホストメモリ(またはデュアルOpenCAPI 25Gx8)とのGen3x16 PCIe接続、および他のFPGAボードまたは100Gイーサネットネットワークへの接続に使用可能な48x 25Gb/sリンクを備えています。
このホワイトペーパーでは、実世界のアプリケーションでこのボードの潜在的なパフォーマンスを評価するために、3つのケーススタディを調査します。それは、多次元FFT、マージソート、マトリックス乗算です。
多次元FFTの実装:
FPGAは、多くの航空宇宙・防衛システムでのFFT実装に最適なデバイスであり、リアルタイムレーダー、ソナー、および通信システムに実装されています。これは、デュアルポートオンチップメモリの非常に高い帯域幅を活用して、アプリケーションに適したビット幅に簡単にカスタマイズできるFFTバタフライ処理エンジン間でデータをバッファリングでき、実装効率が高いためです。大規模なデバイスでの1次元FFTの性能は、IO帯域幅によって制限される場合がありますが、多次元FFTは各段階でデータを使用します。HBMアーキテクチャは結果を保存し、チップパッケージ内で効率的にコーナーターンできるためこのタスクに非常に適しています。FPGAを使用すると、FFT計算用の非常に効率的なアーキテクチャを構築できます。特殊な乗算ロジック(DSPタイル)は、FFTの各ステージにRadix-2またはRadix-4 バタフライコアを実装するための非常に効率的な積和ハードウェアを提供します。ステージ間で、デュアルポートブロックRAMは、読み取りと書き込みを同時に行うことができるバッファーを提供します。 これにより、乗算ハードウェアを完全に利用して、すべてのステージでデータを継続的に実行できるパイプライン実装が可能になります。Figure 1は、FPGAに実装されたパイプラインFFTの一般的な構造を示しています。
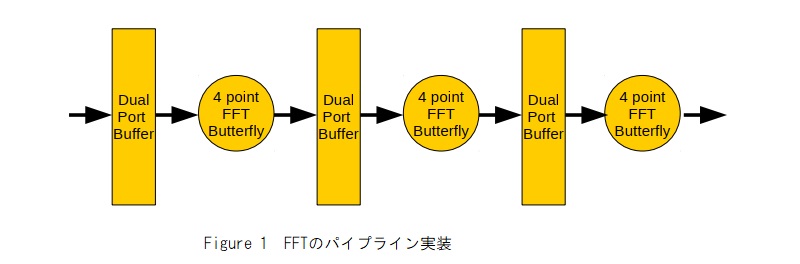
ほとんどのFPGAデザインツールで利用可能なIPコアを使用して、FPGAデザインの効率的な実装をすぐに入手できます。したがって、非常に特殊な要件を満たす必要がない限り、これを最初から実装する必要はありません。VivadoのザイリンクスIPコアは、固定および単精度の浮動小数点実装を提供し、400MHzを超えるクロックレートで実行できます。これらは、さまざまなサイズと構造に構成できます。8192x8192x8192の複雑な単精度3D FFTは4GBのHBM RAMを占有し、8GB VU37Pパーツでの効率的なダブルバッファリングを可能にするため、このペーパーでは8192ポイントの実装に焦点を当てます。ザイリンクスFFT IPコアは、約100個のDSPタイルを使用してクロックサイクルごとに1サンプル、26個の単精度GFLOPSの効果的なパフォーマンスで、単精度8k FFTのパイプライン実装を提供できます。これはFPGAのごく一部しか占有しないため、3D FFTアクセラレータの設計では、これらの多くが並列に実装され、HBMメモリとこれらのコアとの間のデータ転送を効率的に実装するのにも役立ちます。
チップ内の並列実装は、処理性能と利用可能なメモリ帯域幅の両方を完全に活用するために不可欠です。HBMメモリはDDR4ベースであるため、連続した長いバーストを介してアクセスするのが最適であり、ランダムアクセスでデータアクセスがポート幅未満の場合パフォーマンスが低下します。また、メモリは32個の独立した並列256ビット幅AXIポートで構成され、各ポートはチップ内のスイッチロジックを介してHBMアドレス空間全体にアクセスできます。HBMメモリはDRAMデバイスの並列スタックでもあるため、効率的に実現するには、少なくとも256ビット幅のアクセスが必要になります。Figure 2は、一般的なHBMスイッチング構造を示しています。
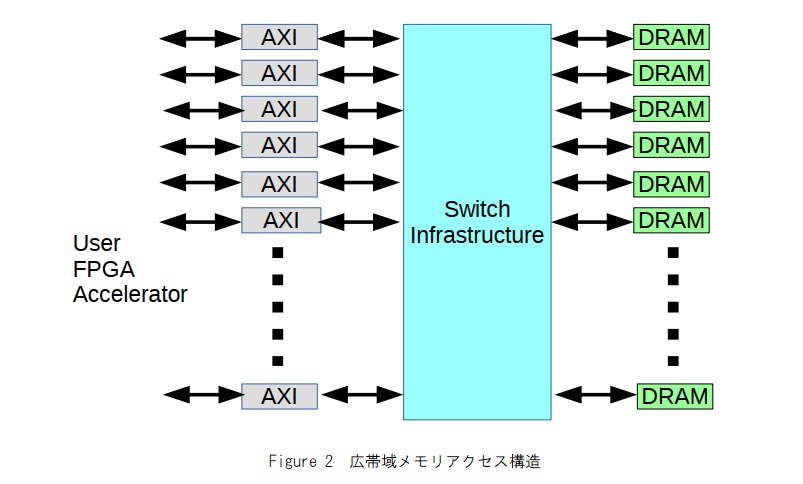
ここでは、メモリアクセスと演算性能の比率が重要です。単一のFFTコアでは、26 GFLOPSのパフォーマンスに一致する3.2 GB/sの連続的な読み取りパフォーマンスが必要です。処理されたデータを書き戻すには、同じ帯域幅が必要です。単一のAXIポートは、この読み取り帯域幅の最大4倍を提供し、それぞれポートが必要な読み取りと書き込みを想定すると、メモリ帯域幅の考慮事項に基づいて、デバイスは最大64コアを並行してサポートできます。
多次元FFTでは、データアクセスパターンはデータがメモリに格納される方法に必ずしも適合しない場合があります。3D FFTでは、各次元で順番にFFTを実行します。最初のパスでFFT入力を読み取ると、X方向は効率的ですが、DRAMからY方向とZ方向のFFTのデータを直接読み取るには、帯域幅の少なくとも75%を無駄にする非効率的な64ビット幅、バースト長1の転送が必要です。この解決策は、FPGA内の内部RAMでデータのコーナーターンを実行することです。これは、別のアクセラレータコアを使用して、メモリからの読み取り中、FFTの書き戻し中、またはFFT転送の間に実行できます。このペーパーでは、最初のオプションについて検討します。
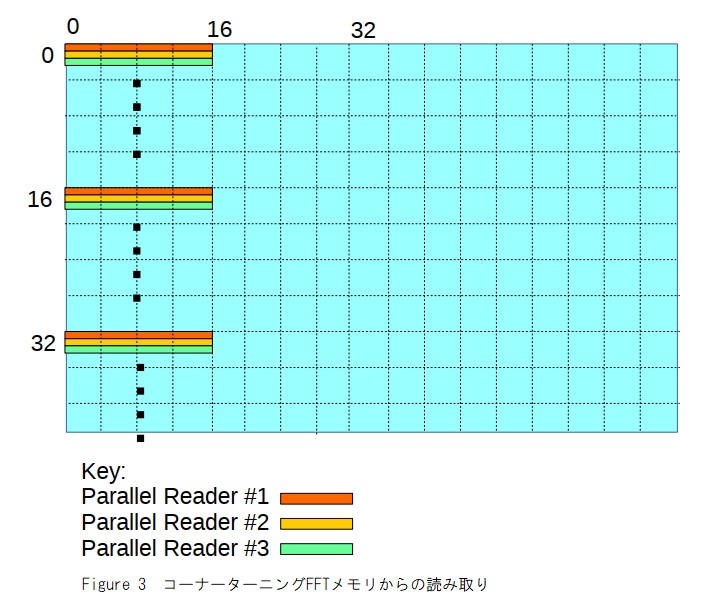
このケーススタディでは、各並列FFTコアがメモリリーダーおよびメモリライターエンジンとペアになっています。メモリリーダーはまず、すべてのパラレルリーダーからのデータを集約し、コーナーターン変換後に出力するコーナーターンブロックを介してデータをプッシュします。X方向の最初のFFTパスでは、このコーナーターンをバイパスできます。Figure 3は、コーナーターンを使用した16個の並列コアのメモリアクセスパターンを示しています。最初のユニットは、最初の行(オレンジで表示)から16チャネル幅のスライスを読み取ります。このDMA読み取りエンジンによる次の読み取りは、17行目、33行目などからです。2番目のDMAエンジンは行2,18,34から読み取り、3番目は3,19,35から読み取ります。コーナーターンブロックは16個のパラレル入力ストリームをすべて受信し、16個のパラレルコーナーターンストリームとして出力します。各FFTコアは、Y方向(Z方向、同じロジックで16行ごとに16リーダーのそれぞれから1サンプルを取得します)行間で異なるアドレスジャンプで動作します。)。
8192のFFTサイズの選択は、この場合、HBMメモリと8192x8192x8192データセットのフットプリントの一致によって動機付けられました。コーナーターニングアプローチは、より大きなFFTサイズの範囲に適しています。メモリ帯域幅により、並列コアの数が事実上64個に制限されるため、4kより小さいFFTサイズは効率が低下します。128x128x128などの小さいFFTサイズでは、FPGA内のオンチップSRAMメモリを使用して、FFTステージ間でコーナーターニングをより効果的に実行できるため、これらのアプリケーションではHBMの使用はそれほど重要ではありません。
このソリューションを実装する場合のリソースの制限は、FFTコア内のダブルバッファーとして使用されるBlockRAMの可用性になります。VU37Pには非常に大きなオンチップSRAMメモリがありますが、その80%はより大きなUltraRAMブロックであり、FFT IPコアでは使用されていません。これにより、FFTコアの数が48に制限されますが、一般的な250MHzシステムクロックを使用して0.75TFLOP(単精度)を超える持続動作が可能な3D FFTコアが得られます。
並列マージソート:
ソートおよび検索アルゴリズムは、多くのアプリケーションの基本的な構成要素です。浮動小数点演算の要件がなければ、それらはアクセラレータの候補として無視されます。これらのアルゴリズムの最適化に関する研究は、多くの場合、いくつかのヒューリスティックな手段を介して、比較操作の数を最小限に抑えることにのみ焦点を当てています。ただし、FPGAの実装では、比較操作が実際に処理コストと処理時間の重要な部分ではないことは明らかです。データをメモリから比較ユニットに移動したり、比較ユニットに戻したりする際に、はるかに多くのパフォーマンスとエネルギーが使用されます。したがって、比較ロジックとメモリの間に大きな帯域幅を持つHBM対応FPGAは、より優れたソリューションを提供できるはずです。FPGA内のUltra RAMおよびブロックRAMは、データキャッシングとデータフローのアプリケーション固有の制御を可能にし、高性能で低エネルギーのソリューションを提供するのにも役立ちます。
マージソートは、通常FPGA実装で考慮されるアルゴリズムではありません。ただし、大規模なデータセットの場合、これは決定論的で効率的な並べ替えアルゴリズムであり、簡単に並列化できます。算術要件は最小限です。オンチップメモリの柔軟な構成により、非常に効率的な低電力ソリューションを提供できます。計算は最小限であるため、データの移動がこのアルゴリズムのパフォーマンスと電力の要件を支配するため、このアルゴリズムでHBMを使用することには大きな利点があります。ソートのマージは、データをソートするための分割統治アプローチです。確定的な複雑さO(N log2 N)を持ち、ベストケースデータ(クイックソートなど)を使用するいくつかのヒューリスティックアルゴリズムよりも遅い場合がありますが、データ依存の問題はありません。また、並列化可能であるため、FPGA実装により適しています。O(N log2 N)の複雑さはFFTアルゴリズムのそれに類似しており、前のケーススタディで説明したのと同様のデータフロー構造を使用し、パイプラインを通してlog2 Nの並列性を作成できます。これにより、ソート時間O(N)は、データをメモリから読み取り、書き戻すことができるレートと効果的に一致します。
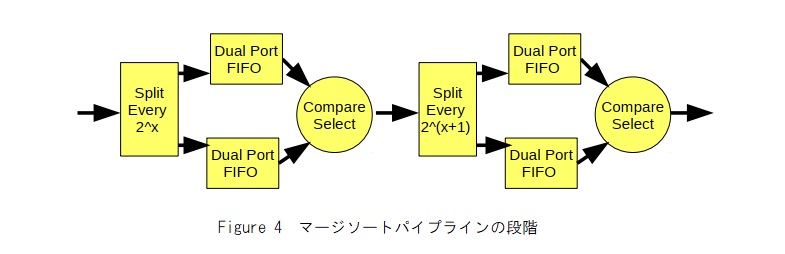
Figure 4は、マージソートパイプラインの2つの段階を示しています。各段階で、入力ストリームは2つのFIFOに分割され、比較演算を使用して最初に大きな出力を選択し、次の段階に掃出します。入力データストリームは、2つのFIFOのいずれかに代替的に供給されます。最初の段階では、データはソートされていないため、代替要素が各FIFOに送信されます。後の段階で、入力データは2つの長いセクションに分類されるため、この要素数の後に分割が行われます。各ステージで1つのFIFOから2x要素が読み取られると、2(x+1)のソートされた要素が出力されるまで、残りのデータが他のFIFOから読み取られます。
比較および選択操作のためのFPGAリソース要件は比較的最小限であり、必要なロジックセルはわずかです(280万個が利用可能と考えられます)。最大のパフォーマンスを得るために、比較演算はハードコーディングされており、例では64ビットビッグエンディアン比較(テキスト文字順)ですが、より複雑な比較(たとえば、整数の64ビットリトルエンディアン、またはバイトごとの大文字と小文字を区別しないASCIIの比較)を簡単に実装することもできます。実行時に、ソフトウェアで選択可能な比較ユニットをわずかな追加ロジックコストで追加することもできます(必要な可能性のあるすべての比較を効果的に実装します)。データ幅の柔軟性は低く、データ要素は比較に使用される値とその他のデータ要素に分割されて、並べ替えに使用される必要があります。サンプルのケーススタディでは、8バイト値は8バイトキーとペアになっており、比較には使用されませんが、参照データベースへの64ビットポインターである可能性があります。このアクセラレータでリソースを使用するコンポーネントはFIFOです。各段階で、FIFOの深さは2x要素である必要があります。これにより、FPGAに収まるステージ数に事実上制限が設けられます。さらに、HBMデバイスでは、追加のステージでHBMデバイスのあるポートから別のポートにソートをマージできます。VU37Pデバイスを使用して16バイト幅のデータレコード(8バイトの比較可能な値、8バイトのキー/ポインター)を選択し、分散RAM、ブロックRAM、ウルトラRAMからFIFOを構築して20の並列ステージを構築し、並列処理を可能にします。 メモリポートの読み取り速度で、O(N)時間で100万を超える要素(16MB)をソートします。他のHBMポートを使用して追加のステージを追加すると、さらに8種類のソートをパイプラインに配置でき、O(N)時間で4GBのデータをソートできるようになります。
倍精度行列乗算:
線形代数ライブラリは多くのHPCアプリケーションの中心であり、行列乗算は最も一般的に使用される演算の1つです。単純な実装では、行列乗算はO(N3)ですが、メモリ帯域幅の要件はO(N2)です。FPGAは、各乗数ユニットの行と列のデータをそのユニットのローカルにキャッシュできる固定サイズのNユニットを効率的に実装できます。ローカルメモリと処理リソースはNのサイズを制限します。値を大きくするとメモリ帯域幅の制限を克服できますが、値を小さくすると柔軟性が高まり、より多くのマトリックスサイズをより効率的にサポートできます。HBMデバイスはFPGAマトリックス乗算コアのより良い利用を可能にします。通常、固定乗算サイズのニーズは、反復ループ内での加算、転置、スケーリングなどの単純なメモリバウンド操作と組み合わされ、HBM帯域幅とマルチポート構造により、これらの追加操作が同じデータで可能になります。そして、データセットをデバイス上でローカルに保持します。
O(N3)よりも優れたパフォーマンスを実現できる行列乗算アルゴリズムがいくつかありますが、これらは特定のデータセットに対して安定性の問題があるか、ほとんどの実用的な用途に適さない他の計算の複雑さを持っています。したがって、ほとんどのアルゴリズムは、未処理のO(N3)実装を使用する傾向があります。O(N3)計算の場合、O(N2)メモリアクセスのみが必要なため、これは必ずしもメモリバウンドではありません。したがって、メモリアクセスに対する計算の比率はO(N)であるため、メモリバウンドの問題を回避するためにNを増やすと状況が改善されます。ただし、これを実現するには、適切な行と列のデータを各乗算ユニットの近くにキャッシュする必要があります。CPUシステムではこれにより、小さなマトリックスサイズで非常に高速なパフォーマンスが得られ、キャッシュミスが支配的な大きなマトリックスサイズでパフォーマンスが低下します。FPGA実装では、デュアルポートメモリにより、現在のマトリックス計算が進行している間に次のマトリックス操作データをロードできるダブルバッファードキャッシュの実装が可能になります。アルゴリズム内でデータを再利用するO(N)要素があるため、メモリからキャッシュへの書き込みは計算よりもはるかに短い時間で済み、キャッシュの依存関係が回避されます。FPGAマトリックス乗算コアは、N個の浮動小数点乗算ユニットで構成できます。各ユニットには、最初のマトリックスの列と2番目の行列の行を含む2つのローカルキャッシュメモリがあります。これら2つのベクトルの乗算を反復処理すると、NxNの結果ごとに部分積が生成され、N-1倍精度浮動小数点加算器を備えた加算器ツリーパイプラインを使用して、他の乗算ユニットからのすべての積と合計できます。Figure 5は、行列乗算のためのこのシストリック配列構造を示しています。キャッシュラインの読み取りからマトリックス製品要素の出力までのレイテンシは非常に長く、倍精度の乗算レイテンシにlog2(N)倍の加算レイテンシを加えたものです。ただし、N2乗算に比べて、この時間は小さくなり、最後のデータの読み取りが終了した直後に次の行列乗算を開始できるため、パフォーマンスにとってレイテンシは重要ではない場合があります。
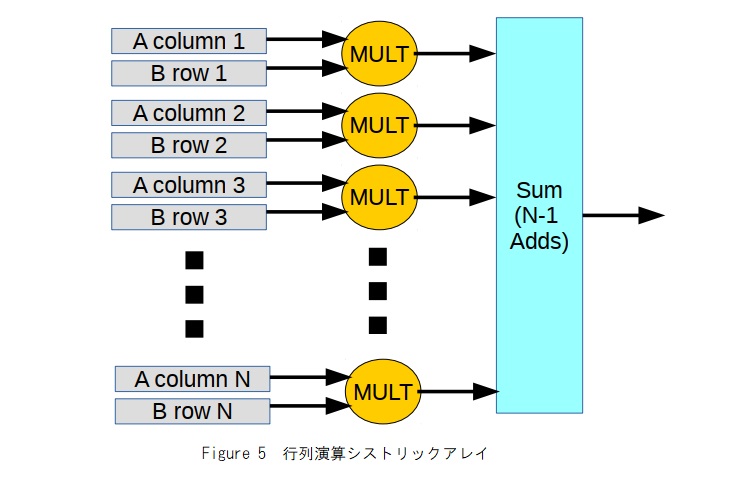
ローカルキャッシュは、ブロックRAMまたはウルトラRAMを使用してFPGAに実装されます。これにより、これらのブロックにサイズ制限が設定され、2のべき乗のサイズになります。Nの2のべき乗以外の並列化では、これによりメモリ使用効率が低下します。データをダブルバッファリングし、外部メモリからのデータロードを前のデータフレームのマトリックス操作と並行して実行できるようにするには、キャッシュのサイズが少なくとも2Nである必要があります。ブロックRAMコンポーネントは、当然512個のディープメモリーにマップされるため、最大256ユニットの並列化をサポートします。256から512に移動すると、並列化Nに比例してRAM要件が増加するだけでなく、512の並列化を超えて移動する場合と同様に、各ローカルバッファーサイズを2倍にする必要があります。この制限を念頭に置いて、使用される行列乗算コアは、可能な限り多くのVU37Pを満たすようにスケールアップされました。512のNを使用した場合、必要な計算リソースは50%未満でしたが、RAMの50%以上が必要でした。1024の並列化までのスケーリングは不可能と思われますが、並列704×704倍精度マトリックス乗算器は適合します。250MHzでクロックされた場合、これは約350 GFLOPSのパフォーマンスになります。
これまでに説明した行列乗算の実装は、メモリ帯域幅が制限ではないため、非HBM FPGAでも同等に機能します。HBMを使用する利点は、行列乗算演算を他の行列演算と組み合わせると明らかになります。行列乗算コアは2つのマトリックスから読み取り、1つのマトリックスに書き戻すため、最大3つのHBM AXIポートを使用してメモリにアクセスできます。これにより、他の多くのポートが自由に並行して演算を実行できます。1つの便利な操作は、要素の追加による行列要素です。これは、より大きなマトリックスを乗算するための分割統治アルゴリズムの一部として使用でき、コアがその固定サイズよりもはるかに大きなマトリックスを処理できるようにします。コアは、未使用の行と列をゼロに設定することにより、より小さいマトリックスを処理することもできます。ただし、計算時間は完全な行列サイズと同じ時間かかるため、これは比較的非効率的です。
将来の作業では、単一の大きなマトリックス乗算コアの代わりに複数の小さなコアを使用することの利点と欠点を検討します。これは、HBMへのマルチポートアクセスによりHBMパーツに簡単に実装できます。これは、追加のマトリックス加算操作だけでなく、マトリックススカラー乗算、マトリックスベクトル乗算、マトリックス転置、および要素ごとのレシプリコルまたは平方根など、大規模なMatrix-Matrix製品オペレーションのHPCアプリケーションループでよく使用される他のいくつかのマトリックス操作と組み合わせることができます。これらの操作の一部をパイプライン化してメモリ要件を削減できます。たとえば、メモリに書き戻す前に行列積の平方根を計算します。
結論:
このホワイトペーパーでは、Alpha Data ADM-PCIE-9H7アクセラレータカードで実行されるXilinx Virtex Ultrascale+ HBM VU37Pデバイスでの3つのアプリケーションケーススタディの実装について説明しました。従来のFPGAは、FFT実装に非常に効率的なメカニズムを提供しますが、大規模な多次元ワークロードの場合、広帯域幅の並列HBMインターフェイスは、特に効率的なデータのコーナーターニングを可能にするFPGAオンボードメモリの柔軟性と組み合わせた場合、これらの大きなデータセットを処理するための完璧なバッファーを提供します。並列マージソートは、HBM FPGAデバイスをターゲットにすることもできます。VU37Pの大規模なFPGAサイズ、特にUltra RAMの大規模な提供により、最大20の並列ステージでのソートパイプラインの非常に効率的な実装が可能になり、100万を超える要素のメモリ読み取り速度でソートされます。HBMでは、追加の並列ソートステージをパイプラインで動作させ、ソートサイズを数桁拡張できます。大規模な並列行列乗算コアはほとんどの大規模FPGAに実装できますが、これらの実装は特にメモリ帯域幅の影響を受けません。ただし、HBMを使用すると1つ以上の行列乗算コアと、より基本的な低パフォーマンスの追加やスケーリングなどのメモリバウンドオペレーターを簡単に組み合わせて、より複雑な処理ループを実行しながらデータセットをアクセラレータに保持できます。最大8GBのサイズの同じ作業データセットへのこのマルチポートパラレルアクセスにより、同じFPGAデザインにアクセラレータの多くの組み合わせを実装できます。たとえば、行列乗算とFFT処理の組み合わせには多くのアプリケーションがあります。
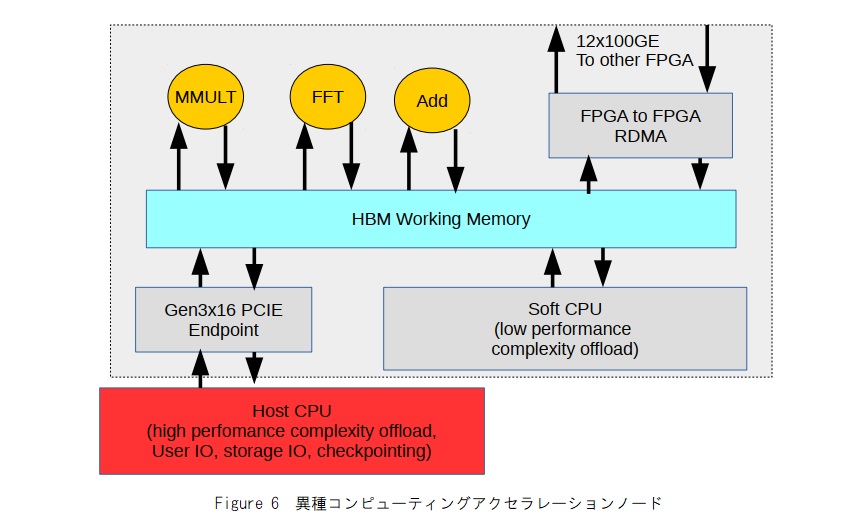
複数のヘテロジニアスアクセラレーションコアを備えたコンピューティングアクセラレーションノードのこのアーキテクチャのアイデアは、ほぼ汎用のメモリとデータフロー中心のパラダイムに拡張できます。アプリケーションの作業データはHBMメモリに保持され、処理はこれを中心に動作します。Figure 6は、そのような構造の1つを示しています。FPGAには、さまざまなアクセラレータとワークモジュールが含まれています。シンプルで複雑な計算アクセラレータは、HBMメモリ上で直接動作します。制御およびモードの複雑なタスクは、オンチップソフトCPU、またはPCIeを介したホストCPUによって処理できます。ノード間通信は並行して動作し、クラスター内の異なるFPGA間で1.2TB/sのIO帯域幅を介してデータをシフトします。
——————————————————————
原文ドキュメント:Alpha Data社
ad-an-0066_v1_1.pdf
Breaking Memory Bandwidth Barriers using HBM FPGA
関連製品

ADM-PCIE-9V5:Virtex UltraScale+ FPGA アクセラレータボード (PCIe)
Alpha Data社について
Alpha Data社は、1993年に設立され、計算集約型アプリケーションをターゲットとした最先端のFPGAソリューションを提供しており、FPGAアクセラレータのマーケットリーダとして市場を牽引しています。主な製品はVPX、XMC、PMC、PCI、CompactPCI、PCIExpress、VXS、VMEなどのA/D, D/A, FPGAボードやCameraLink等のデジタルI/Fを搭載した信号処理ボードです。ボーイング、ロックウェルコリンズ、JPL、ロッキードマーチン、モトローラ、BAEなどのミリタリ向けやデータセンター向けに広く採用されています。Alpha Data社の詳細については、https://www.alpha-data.com/を参照してください。